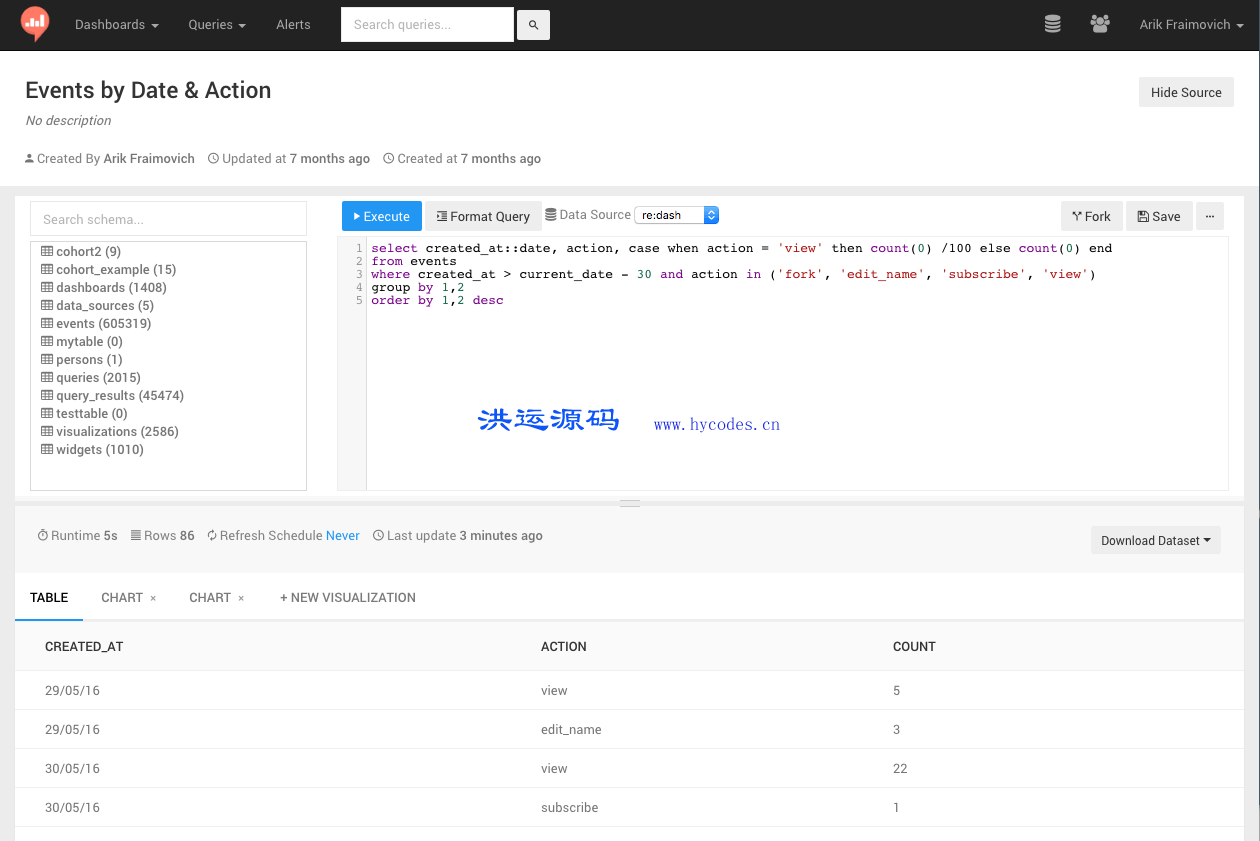
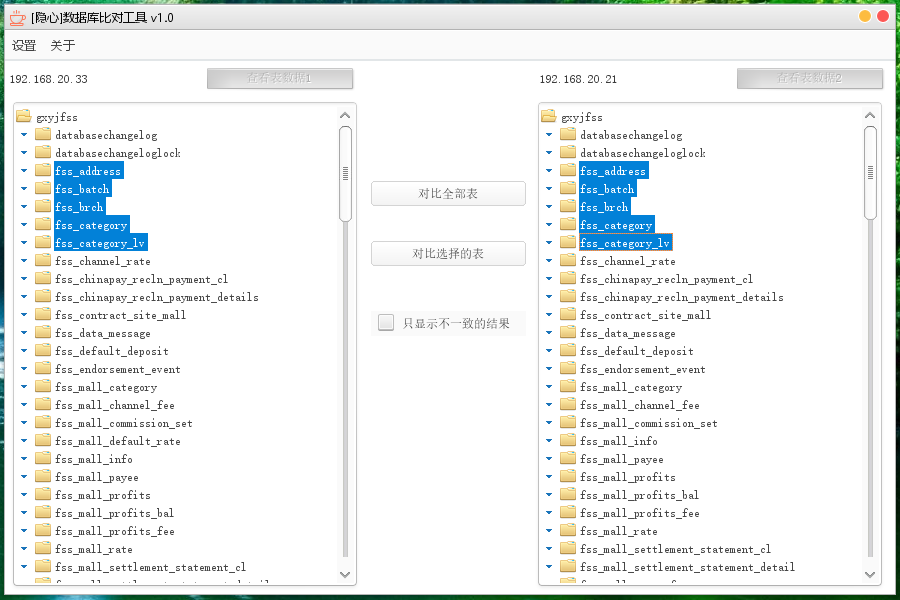
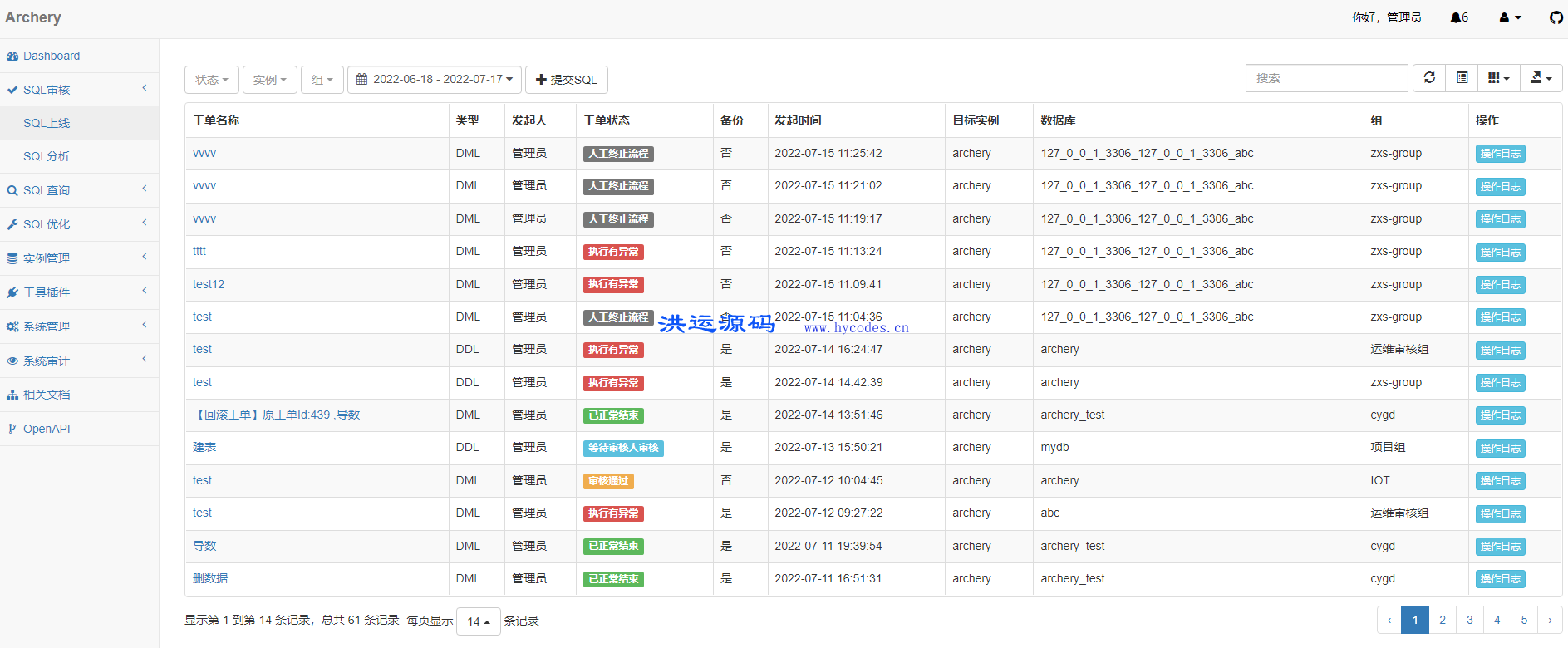
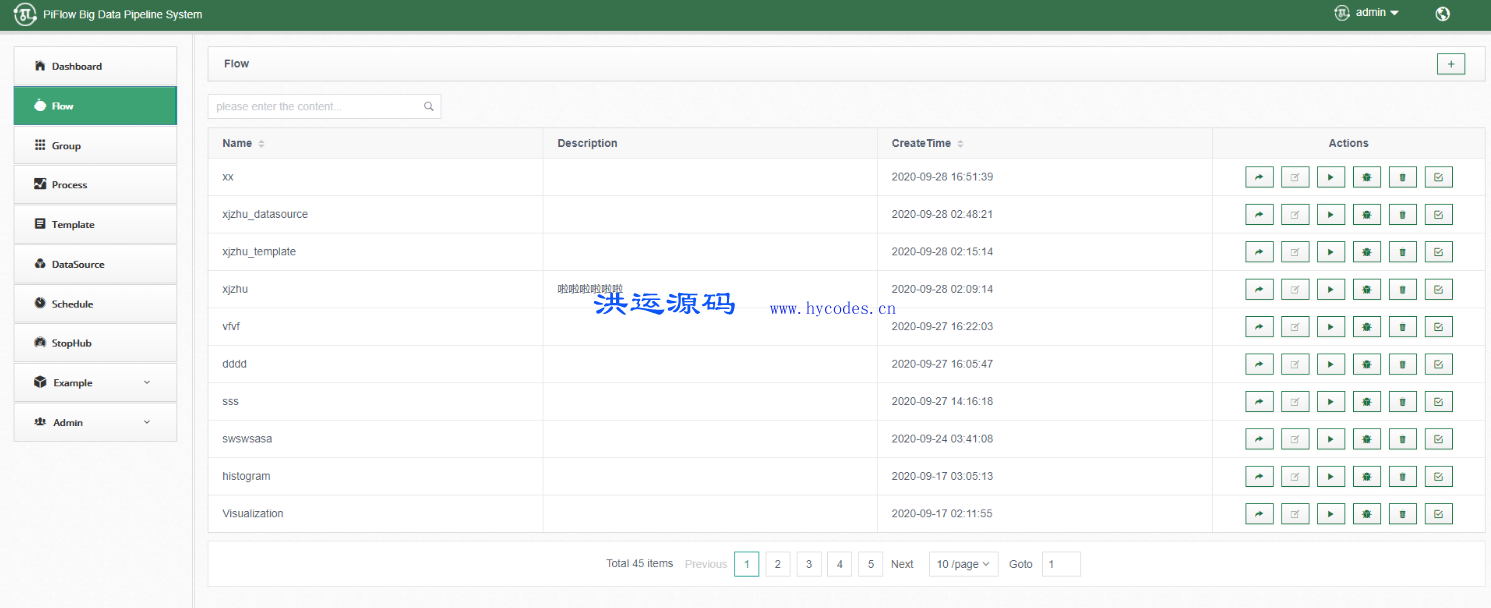
PiFlow是一个简单易用,功能强大的大数据流水线系统。包含丰富的处理器组件,提供Shell、DSL、Web配置界面、任务调度、任务监控等功能。
特性:
1、简单易用
可视化配置流水线。
监控流水线。
查看流水线日志。
检查点功能。
2、扩展性强:
支持自定义开发数据处理组件。
3、性能优越:
基于分布式计算引擎Spark开发。
4、功能强大:
提供100+的数据处理组件。
包括Hadoop 、Spark、MLlib、Hive、Solr、Redis、MemCache、ElasticSearch、JDBC、MongoDB、HTTP、FTP、XML、CSV、JSON等。
集成了微生物领域的相关算法。
环境要求:
JDK 1.8
Spark-2.11.8
Apache Maven 3.1.0
Spark-2.1.0 及以上版本
Hadoop-2.6.0
")
标签:
PiFlow(大数据流水线系统)v1.6 源码链接:https://www.hycodes.cn/sjgl/1160.html
下载说明:本站部分资源供学习交流使用,如商业用途,请购正版。
上一篇:HikariCP JDBC连接池
下一篇:pdmaner元数建模